
Mete Ismayilzada, Debjit Paul, Syrielle Montariol,
Mor Geva*, Antoine Bosselut
EPFL, * Google DeepMind
Abstract
Recent efforts in natural language processing (NLP) commonsense reasoning research have yielded a considerable number of new datasets and benchmarks. However, most of these datasets formulate commonsense reasoning challenges in artificial scenarios that are not reflective of the tasks which real-world NLP systems are designed to solve. In this work, we present CRoW, a manually-curated, multi-task benchmark that evaluates the ability of models to apply commonsense reasoning in the context of six real-world NLP tasks. CRoW is constructed using a multi-stage data collection pipeline that rewrites examples from existing datasets using commonsense-violating perturbations. We use CRoW to study how NLP systems perform across different dimensions of commonsense knowledge, such as physical, temporal, and social reasoning. We find a significant performance gap when NLP systems are evaluated on CRoW compared to humans, showcasing that commonsense reasoning is far from being solved in real-world task settings. We make our dataset and leaderboard available to the research community.
What is it?

CRoW is a multi-task benchmark to evaluate commonsense reasoning ability of AI models in solving real-world tasks where this ability is required.
The benchmark includes 6 diverse real-world NLP tasks:
- Open-domain Dialogue
- Dialogue Summarization
- Intent Detection
- Safety Detection
- Stance Classification
- Machine Translation (en-de, en-fr, en-ru, zh-en)
How is it built?
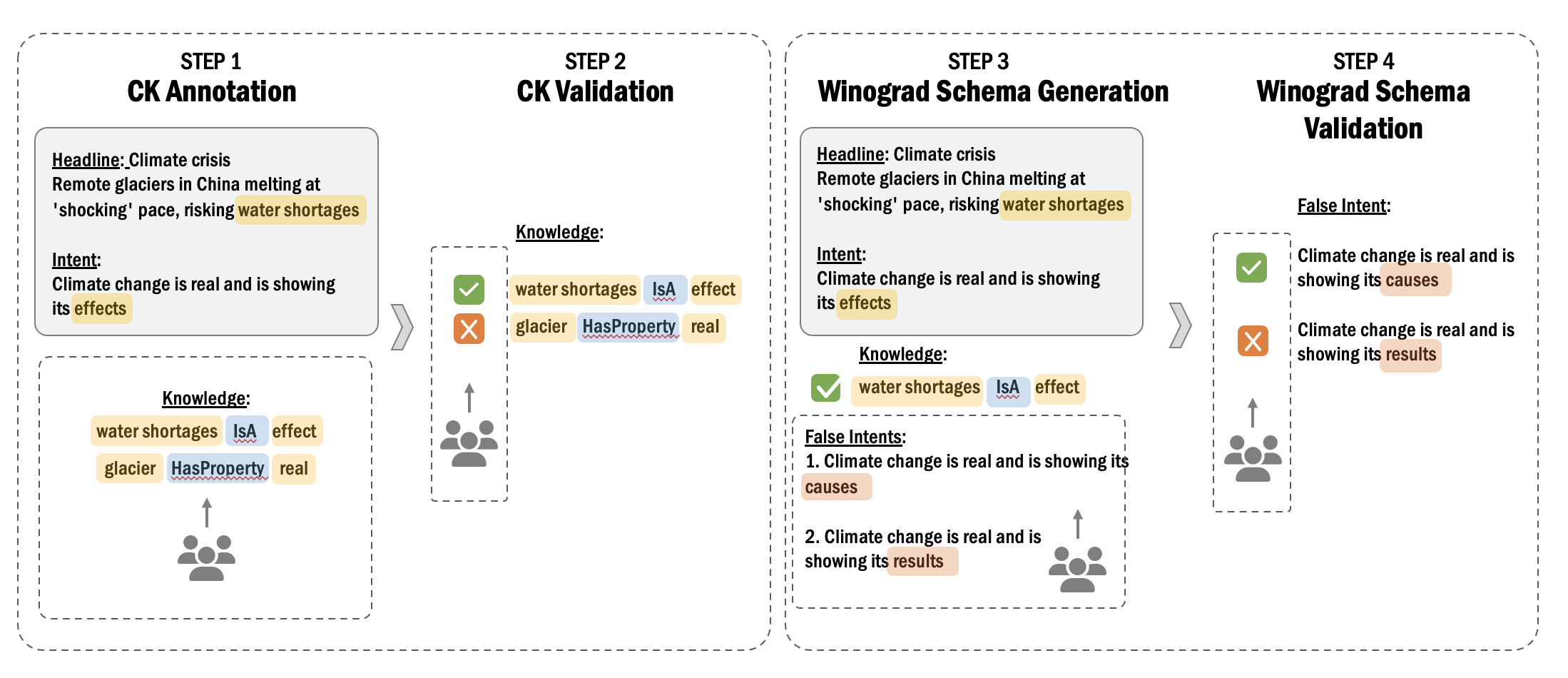
We design a common multi-stage data collection pipeline for generating commonsense-based Winograd-style variations of examples, which can be applied to many tasks. This multi-stage approach has two key benefits. First, we can ground the perturbations to commonsense dimensions, ensuring the Winograd schemas differ on commonsense violations. Second, a particular stage can be skipped if the data for it is already available, which is the case for several tasks in our benchmark.
Cite
Please also consider citing the original datasets used to construct this benchmark which can be found in Tasks section.